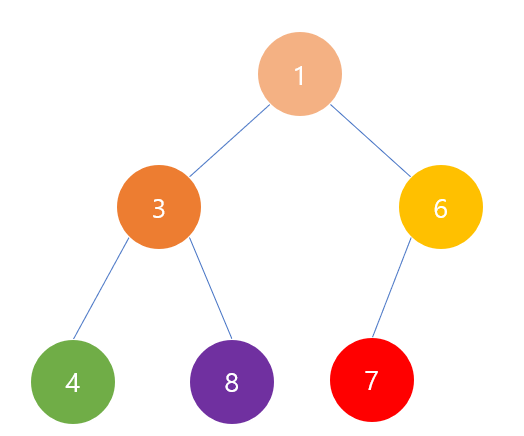
이진 탐색 트리(binary search tree)는 자료 구조의 하나로, 그래프의 트리 구조를 사용합니다. 이진 탐색 트리에서는 각 노드에 데이터가 저장됩니다. - 책 알고리즘 도감 1. 이진 탐색 트리의 구조와 특징 이 그림은 이진 탐색 트리의 예입니다. 각 노드에 적혀 있는 숫자가 데이터입니다. 여기에서는 같은 숫자는 존재하지 않는다고 가정하고 설명하겠습니다. 이진 탐색 트리는 두 가지 특징을 가지고 있습니다. 첫 번째 특징은, 모든 노드는 왼쪽 가지에 포함되는 어떤 숫자보다도 큰 숫자가 된다는 것입니다. 예를 들어, 노드 9는 그 왼쪽에 있는 가지의 모든 숫자보다 큽니다. 마찬가지로, 노드 15는 그 왼쪽 가지에 있는 어떤 숫자보다 큽니다. 두 번째 특징은, 모든 노드는 그 노드의 오른쪽 가지에 ..